Exceptionally well written, impressively organized, and accessibly presented, “Turning Numbers into Knowledge: Mastering the Art of Problem Solving” is an ideal textbook for college and university library Business & Economics collections and supplemental studies curriculums.
There’s been a lot written over the past couple of years about the electricity used to mine Bitcoin, the most prominent of many cryptocurrencies. I can best summarize the credibility and tone of that coverage with the following headline from Newsweek:
This kind of headline makes me cringe, because it’s
1) an invalid extrapolation of oversimplified calculations that are no better than guesses that may mislead investors into taking rash actions; and (less importantly)
2) Bitcoin mining uses electricity, not (usually) other forms of energy.
I’ve been studying the electricity used by computing equipment for more than two decades, so I have some things to say about this latest outbreak of people taking leave of their critical faculties.
In this post, I lay out my thoughts about how sensible people can avoid being misled by the hype machine on Bitcoin electricity use. I created a blog page that lists the recent links I’ve been able to find on this topic, which you can find here.
I’m making no judgment here about whether Bitcoin is something that society shouldbe doing, just focusing on the narrow question of what we know about the estimates of electricity used by Bitcoin currently making the rounds.
PRELIMINARIES
Bitcoin is what’s called a “cryptocurrency”, which is a digital medium of exchange and a store of value under decentralized control (unlike traditional currencies that are created and regulated by governments). The technology underlying Bitcoin and other cryptocurrencies is what’s called “block chain”, which is a decentralized way to establish and maintain trust among people interacting with each other.
Bitcoin is a public, permissionless block chain that uses what’s called “proof of work” to establish this trust. There are other types of block chains, and in some cases these can be designed to be less computationally and energy intensive than Bitcoin. I’ll explore the implications of this fact below.
There are at least a couple of credible academic studies of Bitcoin electricity use (O’Dwyer and Malone 2014 and Vrankan 2017), but things change so fast in this field that estimates become outdated in weeks or months.
BRANDOLINI’S LAW GOVERNS
In 2014, and Italian software developer named Alberto Brandolini made the following trenchant observation, which has come to be known as Brandolini’s law, or the BS asymmetry principle (where BS stands for bull manure in polite company):
The amount of energy needed to refute BS is an order of magnitude bigger than to produce it.
This “law” encapsulates one important reality of living in the digital age: it’s easier to create ostensibly accurate but incorrect numbers than it is to demonstrate why such numbers are invalid. That is the nature of careful analysis, but people have come to expect instant answers on new topics, even when there isn’t any real data or research. That’s the case for Bitcoin electricity use, which has emerged as a topic of wide public interest only in the past couple of years.
My corollary to Brandolini’s law is that
In fast changing fields, like information technology, BS refutations lag BS production more strongly than in fields with less rapid change.
Information technology changes at a much more rapid pace than many other technologies (Nordhaus 2007, Koomey et al. 2011, Koomey et al. 2013, Koomey and Naffziger 2016). Unfortunately, innumerate observers love to mindlessly extrapolate rapid exponential growth rates to create “clickbait” headlines like the one in Newsweek I cited above. There’s also a tendency to assume that because information technology is economically important that it also must use a lot of electricity, but that’s just not the case.
Here are a couple of historical examples.
In 2003, writing in IEEE Spectrum, I cited an anecdote from Andrew Odlyzko, formerly at AT&T, now at the University of Minnesota (Koomey 2003). Odlyzko documented the genesis of a familiar “factoid” from the mid-1990s (“the Internet doubles every 100 days”) that led to a substantial overinvestment in the fiber optic network. This misconception
was based on data reported by UUNet, the first commercial Internet service provider, in the mid-1990s. In those days, at least for a brief time, such growth rates actually prevailed. But for almost all the rest of the 1990s, data flows were doubling only every year or so, as documented by Kerry Coffman and Andrew Odlyzko of AT&T Corp. and reported by The Wall Street Journal in 2002.
The difference between the two growth rates is huge: because of the magic of compounding, a doubling of traffic every 100 days translates into growth of about 1000 percent a year, rather than the 100 percent-a-year growth represented by an annual doubling.
During the dot-com boom, industry leaders, investment analysts, and the popular press repeated that gross overestimate of the growth of Internet data flow. The bogus figures helped justify dubious investments in network infrastructure and contributed greatly to overcapacity in the telecommunications and networking industries. Only a tiny fraction of this network capacity is now [circa 2003] being used, and billions of dollars [were] squandered because of blind acceptance of flawed conventional wisdom.
Misleading factoids about information technology electricity use emerged from coal-industry funded studies around the year 2000, at the time of the first dot com bubble and the California electricity crisis. They popped up again, from the same authors and funders, in 2005and 2013. The claims were reported in every major newspaper, cited by investment banking reports and politicians of both political parties, and avidly promoted by people and companies who should have known better.
The authors claimed that the Internet used 8% of US electricity in 2000, that all computers (including the Internet) used 13%, and that the total would grow to 50% of US electricity in 10 years. The authors also claimed that a wireless Palm VII used as much electricity as a refrigerator (later updated to an iPhone using as much electricity as TWO refrigerators) for the networking to support its data flows.
All of these claims turned out to be bunk, but it took years of creating peer reviewed research to prove it. We found that the Internet (defined as those authors defined it) used only 1% of US electricity in 2000, all computers used 3%, the total would never grow to half of all electricity use, and that the factoid about the wireless Palm VII overestimated networking electricity by a factor of 2000. In virtually every case, we found that those authors had overestimated electricity used by computing equipment. For a summary of these claims and a review of their effects on investors, see the Epilogue to the 3rd Edition of Turning Numbers into Knowledge.
These examples came to mind when I first heard about recent claims about Bitcoin electricity use, but the Bitcoin issue has some unique features.
BEWARE OF HAND WAVING ESTIMATES
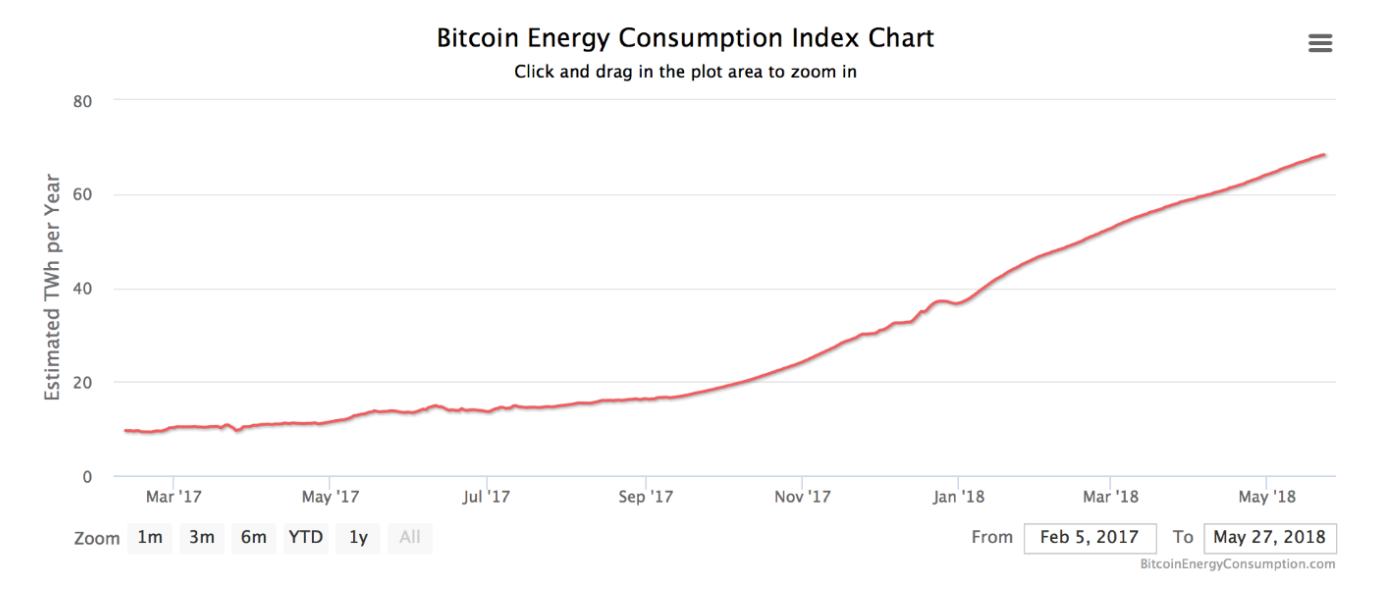
The web site Digiconomist is the source for many media estimates of Bitcoin electricity use. The site is the creation of Alex de Vries, an economist in the Netherlands, and he summarizes his estimates in the form of his “Bitcoin consumption index”. Figure 1 is a screen shot of that index for roughly the past 16 months, showing TWh (terawatt-hours or billion kWh) on the Y-axis and time on the X-axis:
One important feature of cryptocurrency electricity use is that you need to specify the exact day to which your estimate applies. That’s because Bitcoin mining is increasing rapidly over time, so generating a monthly or annual average isn’t accurate enough. Such growth makes estimates from only a couple of years back less useful for estimating current day Bitcoin electricity use than you might expect.
De Vries recently published a commentary article in the journal Joule, in which he summarized the method for generating the Bitcoin consumption index. De Vries is able to create a time series day by day because he generates the index using following data:
1) the price of bitcoin over some time period (it was about $6300 as of today, October 29, 2018);
2) the number of Bitcoins mined over that same time period;
3) an assumption about the percentage of the bitcoin price that is electricity (60%), which would include both direct electrcity use for bitcoin mining rigs and the supporting infrastructure electricity(cooling, fans, pumps, power conversion, etc); and
4) an assumption about the price of electricity (5¢ US/kWh)
Figure 1: Digiconomist Bitcoin Energy Consumption Index
The price of bitcoin over some time period times the number of Bitcoins mined in that period (plus transaction fees) gives total revenues, which are multiplied by 60% to get electricity expenditures. Those expenditures are divided by the assumed electricity price to get electricity consumption of the network in TWh.
The calculation has the advantage of being tractable using available data, but it relies on assumptions about economic parameters and Bitcoin miner behavior (e.g., optimal allocation of mining resources) to estimate physical characteristics of a technological system.
Calculations like these set off alarm bells for me. Economic parameters (like Bitcoin prices) are volatile, and are at best imperfectly correlated with electricity use. In real economic systems, there may be a tendency towards optimality, but they often don’t get close because of transaction costs, cognitive failures, and other imperfections in people and institutions. In addition, the assumptions used by Digiconomist are so simplistic as to make any credible analyst wary.
DOING IT RIGHT
The more direct way to estimate electricity used by equipment is to understand the characteristics of the underlying computing, cooling, and power distribution equipment using field data (as we did for our most recent data center report). Unfortunately, aside from a few anecdotes in the trade and popular press, there’s little information on Bitcoin mining operations.
The servers used for Bitcoin mining are nowadays customized for just that application, and they bear little resemblance to standard server hardware installed in corporate or hyperscale data centers. Because these custom servers have not been tracked by the big data providers (like IDC and Gartner), we have only guesses/estimates as to how many are being built. We know almost nothing about where they’re being installed. And our knowledge of the power systems and cooling equipment in these facilities is virtually nil.
These data issues make it hard to create accurate estimates of electricity used by Bitcoin mining in the aggregate. This is probably why de Vries used his simplified economic approach to generate his index, but that doesn’t mean this method is a reliable indicator of Bitcoin electricity use.
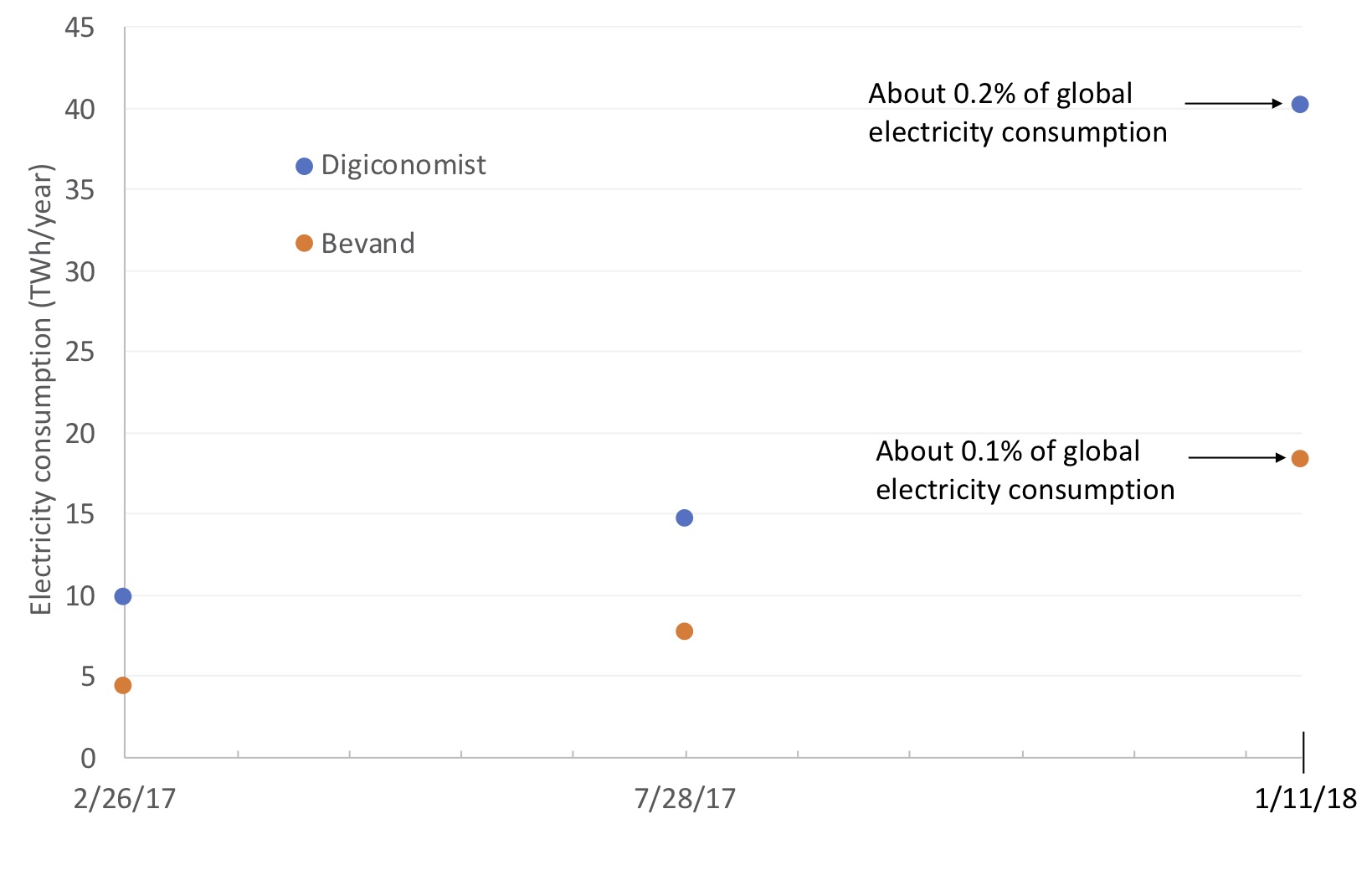
Marc Bevand, an “analyst and crypto[currency] entrepreneur”, critiqued the Digiconomist estimates on February 1, 2017. Most importantly, he expressed concern over the arbitrary choice of 60% of revenues being electricity, and showed a range in his data (based on real equipment) of between 6.3% and 38.6%. Using a more refined approach and more detailed information about the characteristics of Bitcoin mining rigs over time, he estimated Bitcoin electricity use for February 26, 2017, July 28, 2017, and January 11, 2018. Figure 2 compares the Bevand and Digiconomist estimates for those three days.
Bevand did not generate day by day estimates for the intervening periods as Digiconomist does, but these three data points are enough to teach some important lessons. Both sources show growth of about fourfold between February 26, 2017 and January 11th, 2018. That’s rapid growth compared to conventional end-uses, so it’s not surprising that Bitcoin is getting more attention. The big difference is in the absolute electricity consumption. Bevand’s estimates are less than half of the Digiconomist estimates. They also are far more technically detailed and less dependent on high level arbitrary assumptions, which makes them more trustworthy, in my view.
Another important finding from this graph is the relative scale. The world used 21,200 TWh/year in 2016, the latest year for which I could find historical data, and this number increases by only a few percent a year, if history is any guide. This means that on January 11, 2018, Bitcoin accounted for about 0.1% of global electricity if Bevand’s numbers are correct.
Figure 2: Comparison of Digiconomist and Bevand Estimates of Bitcoin Electricity Use
Mining Bitcoin accounts for about 0.1% of global electricity use if Bevand’s estimates are correct, implying that total data center electricity use is about 5% bigger than what IEA estimates (Bitcoin isn’t included in those figures). Without better data, it’s hard to be any more precise than that.
Recent growth rates for Bitcoin mining are substantial, and if that growth continues at anywhere near current rates, Bitcoin electricity use will become more important soon. Continued growth in Bitcoin mining electricity use depends on the price of bitcoin, the difficulty of mining Bitcoin (which goes up as mining speed goes up), and the rate of efficency improvements in Bitcoin mining rigs. It also depends on electricity prices, the cost of mining equipment, and the continued laissez-faire attitude many governments have about Bitcoin (which could change quickly, but no one can predict if or when that might happen).
One thing we should NOT do is recklessly extrapolate recent growth rates for Bitcoin into the future, as the Nature Climate Change article coming out today appears to do (Mora et al. 2018). I cannot emphasize enough how dangerous, irresponsible, and misleading such extrapolations can be, and no credible analyst should ever extrapolate in this manner, nor should readers of reports on this topic fall for this well-known mistake.
Another big uncertainty is that we know even less about other cryptocurrencies than about Bitcoin, so more research is clearly needed there. The electricity use for non-Bitcoin cryptocurrencies should be tallied, both because the total is important and because these other cryptocurrencies (which can be MUCH more energy efficient than Bitcoin) may represent competition to Bitcoin if the electricity demands of Bitcoin become unmanageable.
We urgently need measured data about Bitcoin mining facilities in the field, including characteristics of Bitcoin mining rigs and the power and cooling infrastructure needed to support them. The Digiconomist estimate uses very high level assumptions and data to estimate electricity use, while Bevand creates a more detailed technical estimate, but neither includes much if any field data on actual equipment in real facilities. If we’re to get a better handle on Bitcoin electricity use, such field studies and data are vital.
A colleague (Professor Eric Masanet) and I have secured a small amount of funding to investigate the implications of block chains for electricity use, and that project begins in November 2018. To do such analyses properly (as we did in 2007, 2008, 2011, 2013, and again in 2016 for US data center electricity use) takes teams of scientists and hundreds of thousands of dollars, so it’s no surprise this emergent issue hasn’t yet been carefully studied (EPA 2007, Koomey 2008, Masanet et al. 2011, Masanet et al. 2013, Shehabi et al. 2016). Policy makers naturally want answers quickly, but until more research is funded, there’s not a whole lot more we can say about this issue.
OTHER LESSONS
While I encourage everyone in the electricity sector to track Bitcoin as a potential source of new load growth, please use caution and avoid being misled by the hype. Breathless media coverage papers over the uncertainties in the underlying data, and makes it seem like Bitcoin is taking over the world, but in fact it’s likely only 0.1% of global electricity consumption, and it is unlikely to continue growing at recent historical rates.
Because the rate of change in Bitcoin electricity use can be rapid, it is critically important that no estimates of electricity use be cited or reported unless the day to which that estimate applies is also reported. It is not sufficient to report the year in which an estimate applies, because things change so fast.
If there are many mining facilities proposed in a utility service territory, I suggest that they be charged the full cost of transmission and distribution infrastructure investments up front. Bitcoin mining can disappear just as fast as it rose to prominence, and you don’t want ratepayers to be left holding the bag. I’m not predicting that outcome, just pointing it out as a possibility with real risks to utility ratepayers.
If Bitcoin electricity use becomes more important, we’re likely to face questions about whether to allocate limited zero emissions generation resources to power it. If we use it for Bitcoin, we can’t use it elsewhere, so we’ll have to choose. This concern should factor into the needed societal conversation about whether cryptocurrencies are something we should as a society encourage.
The method for ascertaining trust for Bitcoin is needlessly computationally intensive, and other cryptocurrencies have taken a different tack. Resource intensity can be reduced substantially (i.e., by orders of magnitude) with software and protocol redesign, so it’s not just a question of hardware efficiency. As use cases for cryptocurrencies emerge, we’ll need to confront the possibility that more efficient cryptocurrency designs may be a better fit than Bitcoin for a low emissions world.
CONCLUSIONS
It’s still early days for cryptocurrency and the data on its electricity use are still too poor to derive firm conclusions. The issue bears watching, but caution is indicated, particularly when large investments are involved (like for transmission lines and distribution transformers for new bitcoin mining facilities). Media observers should beware of mindless extrapolations of recent trends, as such simpleminded methods can lead to consequential mistakes. At this point (as of January 11, 2018), Bitcoin mining accounts for about 0.1% of global electricity use, but recent growth has been rapid. What happens next is up to us.
ACKNOWLEDGMENTS
Professor Harald Vrankan of the Open University of the Netherlands and Jens Malmodin of Ericsson gave comments on an earlier version of this blog post. The author is responsible for the blog post itself and any errors contained herein.
REFERENCES
IEA. 2017. Digitalization and Energy. Paris, France: International Energy Agency. [https://www.iea.org/digital/]
Koomey, Jonathan. 2008. “Worldwide electricity used in data centers.” Environmental Research Letters. vol. 3, no. 034008. September 23. [http://stacks.iop.org/1748-9326/3/034008]
Koomey, Jonathan G., Stephen Berard, Marla Sanchez, and Henry Wong. 2011. “Implications of Historical Trends in The Electrical Efficiency of Computing.” IEEE Annals of the History of Computing. vol. 33, no. 3. July-September. pp. 46-54. [http://doi.ieeecomputersociety.org/10.1109/MAHC.2010.28]
Masanet, Eric, Arman Shehabi, and Jonathan Koomey. 2013. “Characteristics of Low-Carbon Data Centers.” Nature Climate Change. vol. 3, no. 7. July. pp. 627-630. [http://dx.doi.org/10.1038/nclimate1786]
Mora, Camilo, Randi Rollins, Katie Taladay, Michael B. Kantar, Mason K. Chock, Mio Shimada, and Erik C. Franklin. 2018. “Bitcoin emissions alone could push global warming above 2°C.” Nature Climate Change. October 29. [https://doi.org/10.1038/s41558-018-0321-8]
Shehabi, Arman, Sarah Josephine Smith, Dale A. Sartor, Richard E. Brown, Magnus Herrlin, Jonathan G. Koomey, Eric R. Masanet, Nathaniel Horner, Inês Lima Azevedo, and William Lintner. 2016. United States Data Center Energy Usage Report. Berkeley, CA: Lawrence Berkeley National Laboratory. LBNL-1005775. June. [https://eta.lbl.gov/publications/united-states-data-center-energy]
US EPA. 2007. Report to Congress on Server and Data Center Energy Efficiency, Public Law 109-431. Prepared for the U.S. Environmental Protection Agency, ENERGY STAR Program, by Lawrence Berkeley National Laboratory. LBNL-363E. August 2. [http://www.energystar.gov/datacenters]
In September 2017 I posted on our analysis of the trends in the electricity intensity of network data flows, which was placed online in August 2017. The journal finally put the article in a printed edition in August 2018 and I wanted to re-up this post (with minor updates) to reflect the actual pub date and the complete reference (see below).
Our previous work on trends in the efficiency of computing showed that computations per kWh at peak output doubled every 1.6 years from the mid 1940s to around the year 2000, then slowed to a doubling time of 2.6 years after 2000 (Koomey et al. 2011, Koomey and Naffziger 2016). These analyses examined discrete computing devices, and showed the effect (mainly) of progress in hardware.
The slowing in growth of peak output efficiency after 2000 was the result of the end of the voltage reductions inherent in Dennard scaling, which the chip manufacturers used to keep power use down as clock rates increased (Bohr 2007, Dennard et al. 1974) until about that time. When voltages couldn’t be lowered any more, they turned to other tricks (like multiple cores) but they still couldn’t continue improving performance and efficiency at the historical rate, because of the underlying physics.
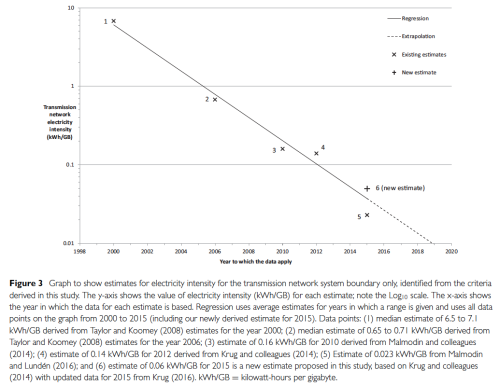
Unlike that for computing devices, the literature on the electricity intensity and efficiency of network data flows has been rife with inconsistent comparisons, unjustified assumptions, and a general lack of transparency. Our attempt to remedy these failings was just published in the Journal of Industrial Ecology in August 2018 (Aslan et al. 2018). The focus is on the electricity intensity of data transfers over the core network and the access networks (like DSL and cable).
Here’s the summary of the article:
In order to understand the electricity use of Internet services, it is important to have accurate estimates for the average electricity intensity of transmitting data through the Internet (measured as kilowatt-hours per gigabyte [kWh/GB]). This study identifies representative estimates for the average electricity intensity of fixed-line Internet transmission networks over time and suggests criteria for making accurate estimates in the future. Differences in system boundary, assumptions used, and year to which the data apply significantly affect such estimates. Surprisingly, methodology used is not a major source of error, as has been suggested in the past. This article derives criteria to identify accurate estimates over time and provides a new estimate of 0.06 kWh/GB for 2015. By retroactively applying our criteria to existing studies, we were able to determine that the electricity intensity of data transmission (core and fixed-line access networks) has decreased by half approximately every 2 years since 2000 (for developed countries), a rate of change comparable to that found in the efficiency of computing more generally.
The rate of improvement is actually faster than in computing devices, but this result shouldn’t be surprising, because the aggregate rates of improvement in data transfer speeds and total data transferred are dependent on progress in both hardware and software. Koomey and Naffziger (2016) and Koomey (2015) showed that other metrics for efficiency can improve more rapidly than peak output efficiency if the right tools are brought to bear on those problems.
Email me if you’d like a copy of the article, or any of the others listed below.
Bohr, Mark. 2007. “A 30 Year Retrospective on Dennard’s MOSFET Scaling Paper.” IEEE SSCS Newsletter. vol. 12, no. 1. Winter. pp. 11-13.
Dennard, Robert H., Fritz H. Gaensslen, Hwa-Nien Yu, V. Leo Rideout, Ernest Bassous, and Andre R. Leblanc. 1974. “Design of Ion-Implanted MOSFET’s with Very Small Physical Dimensions.” IEEE Journal of Solid State Circuits. vol. SC-9, no. 5. October. pp. 256-268.
Koomey, Jonathan. 2015. “A primer on the energy efficiency of computing.” In Physics of Sustainable Energy III: Using Energy Efficiently and Producing it Renewably (Proceedings from a Conference Held March 8-9, 2014 in Berkeley, CA). Edited by R. H. Knapp Jr., B. G. Levi and D. M. Kammen. Melville, NY: American Institute of Physics (AIP Proceedings). pp. 82-89.
Google just released this white paper, which is the next logical evolution in clean energy for data centers (also see the related blog post). When companies claim their data centers use 100% clean electricity, they do that using an annual balancing act, which sometimes isn’t clear to people not familiar with how this works.
Data center developers source clean electricity, like wind or solar, by making long-term contracts with developers to build power plants that otherwise wouldn’t be built. The power plants are sized to generate at least as much electricity as the data center would use over the course of a year, and in that annual sense, they are powering their data centers using clean electricity.
The reality, though, is that in any particular hour, the data center might be drawing more or less power than the wind or solar facility is generating that hour, and accounting for that real time variation is the next obvious step for clean electricity in data centers. There are also other sources of clean electricity on most grids, so those need to be accounted for as well.
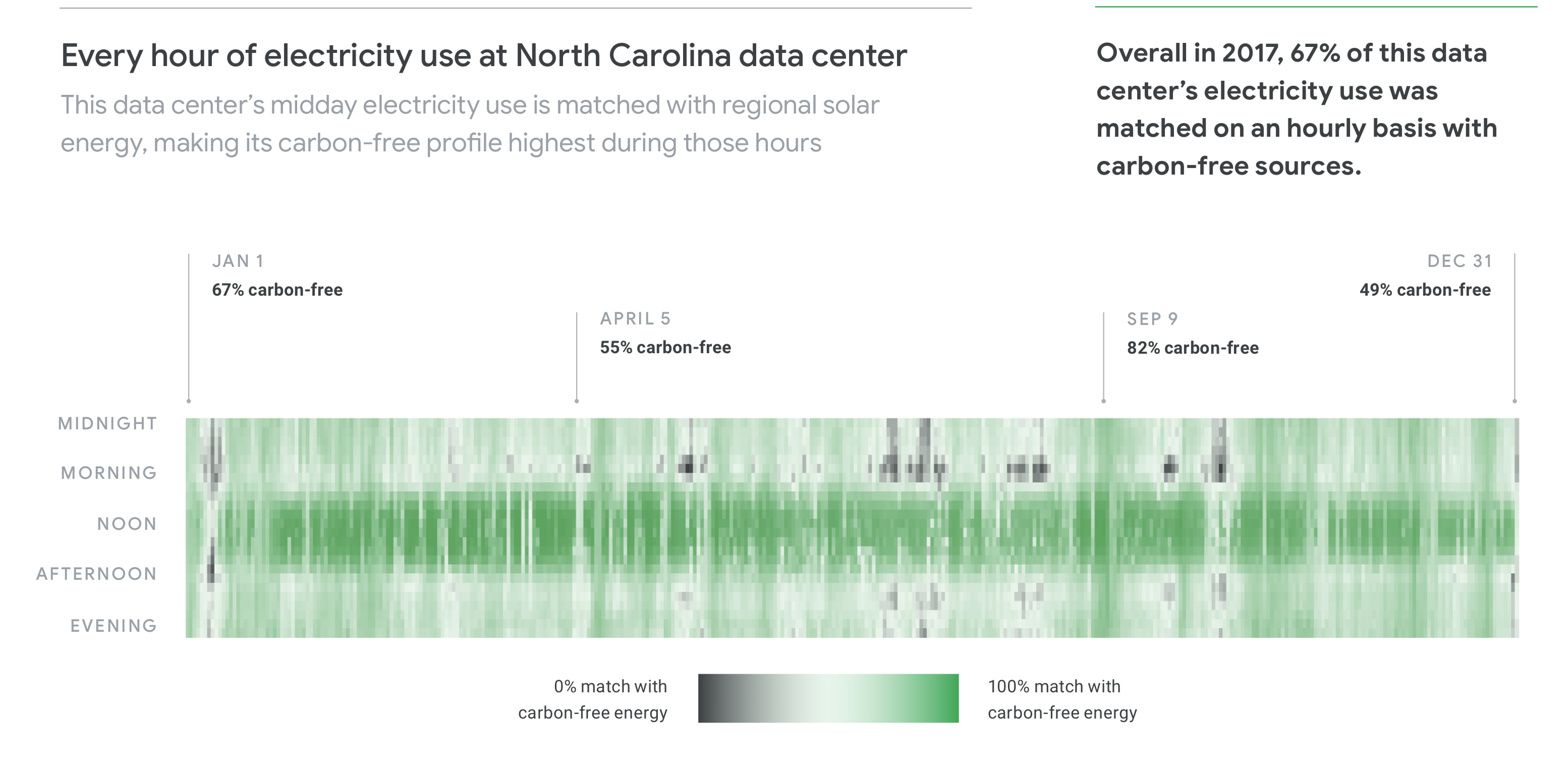
Google’s white paper uses graphs like this one to show visually the hourly variation in clean energy generation’s match with data center electricity use. This one is for their North Carolina facility:
This graph shows the real-time challenge facing any data center facility, and I hope and expect other big data center operators to move to the kind of accounting suggested by Google in their new white paper. As storage becomes more common and clean generation becomes more widespread, this challenge will get easier, but right now we need to get the accounting right in preparation for those developments.
Disclosure: Google asked me to be a technical reviewer for this white paper before its release, which I did without remuneration (because it was worth my time to learn about what they have been up to).
Background
IEA. 2017. Digitalization and Energy. Paris, France: International Energy Agency. November 5. [https://www.iea.org/digital/]
Shehabi, Arman, Sarah Josephine Smith, Dale A. Sartor, Richard E. Brown, Magnus Herrlin, Jonathan G. Koomey, Eric R. Masanet, Nathaniel Horner, Inês Lima Azevedo, and William Lintner. 2016. United States Data Center Energy Usage Report. Berkeley, CA: Lawrence Berkeley National Laboratory. LBNL-1005775. June. [https://eta.lbl.gov/publications/united-states-data-center-energy]
Masanet, Eric, Arman Shehabi, and Jonathan Koomey. 2013. “Characteristics of Low-Carbon Data Centers.” Nature Climate Change. vol. 3, no. 7. July. pp. 627-630. [http://dx.doi.org/10.1038/nclimate1786]
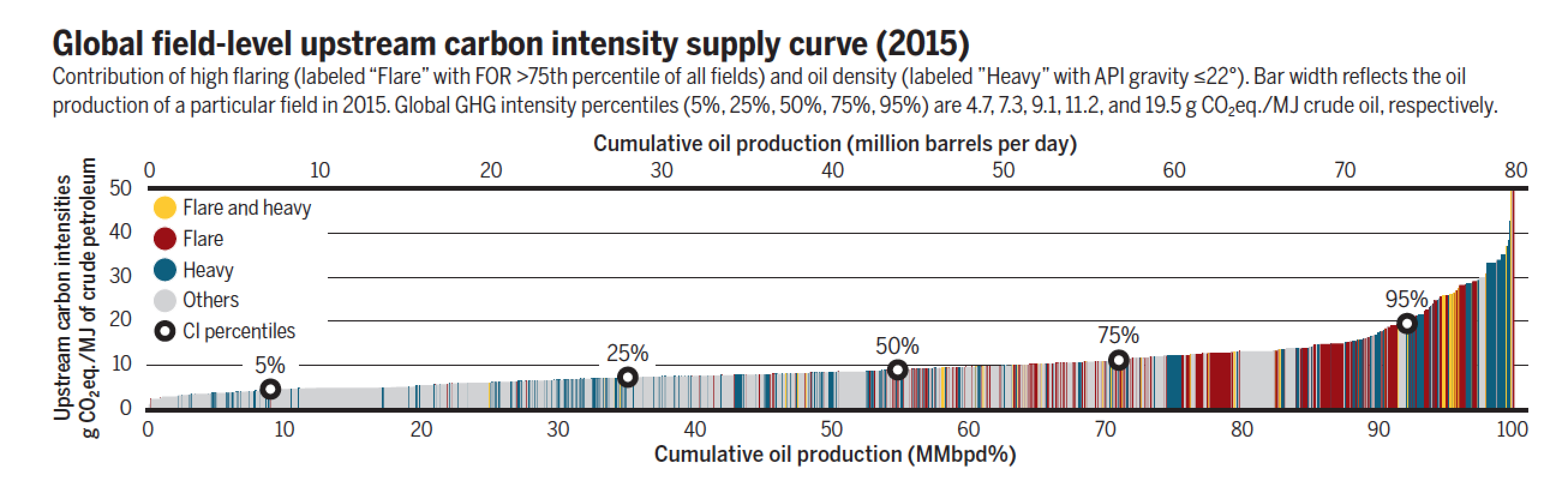
All oil is not created equal when it comes to carbon intensity of production. That’s the message from our latest article, just released in Science today.
This work is part of a broader project to assess the full life-cycle emissions impacts of oil production, refining, distribution, and consumption, summarized in
Policy makers have traditionally treated oil as a uniform commodity, but our work shows variations in total life-cycle emissions that are big enough to matter. The 2nd version of the Oil Climate index (OCI) showed a range of 80-90% from the lowest emitting oil to the highest emitting ones.
We’re in the process of adding more oil fields, updating the methodology, and incorporating life-cycle emissions for about half of the natural gas fields in the world. That update work is due out soon.
Here’s the full reference for the new Science article:
Masnadi, Mohammad S., Hassan M. El-Houjeiri, Dominik Schunack, Yunpo Li, Jacob G. Englander, Alhassan Badahdah, Jean-Christophe Monfort, James E. Anderson, Timothy J. Wallington, Joule A. Bergerson, Deborah Gordon, Jonathan Koomey, Steven Przesmitzki, Inês L. Azevedo, Xiaotao T. Bi, James E. Duffy, Garvin A. Heath, Gregory A. Keoleian, Christophe McGlade, D. Nathan Meehan, Sonia Yeh, Fengqi You, Michael Wang, and Adam R. Brandt. 2018. “Global carbon intensity of crude oil production.” Science. vol. 361, no. 6405. pp. 851. [http://science.sciencemag.org/content/361/6405/851.abstract]
It’s been a great award season for Turning Numbers into Knowledge: Mastering the Art of Problem Solving (3rd Edition). I’m particularly proud of this book because it encapsulates what I’ve learned about being an effective researcher and communicator over the past few decades, and it’s had enough success to warrant creating the 3rd edition, which came out late last year.
I use the book to train employees and students, and it works. I give them the book and say “this book summarizes my expectations for the accuracy of your analysis, the clarity of your presentations, and the thoroughness of your documentation”.
Turning Numbers into Knowledge won Silver awards in the Business Non-Fiction and Professional/Technical Non-Fiction categories in the Global eBook Awards for 2018. To see the list of Global eBook Award winners, go here.
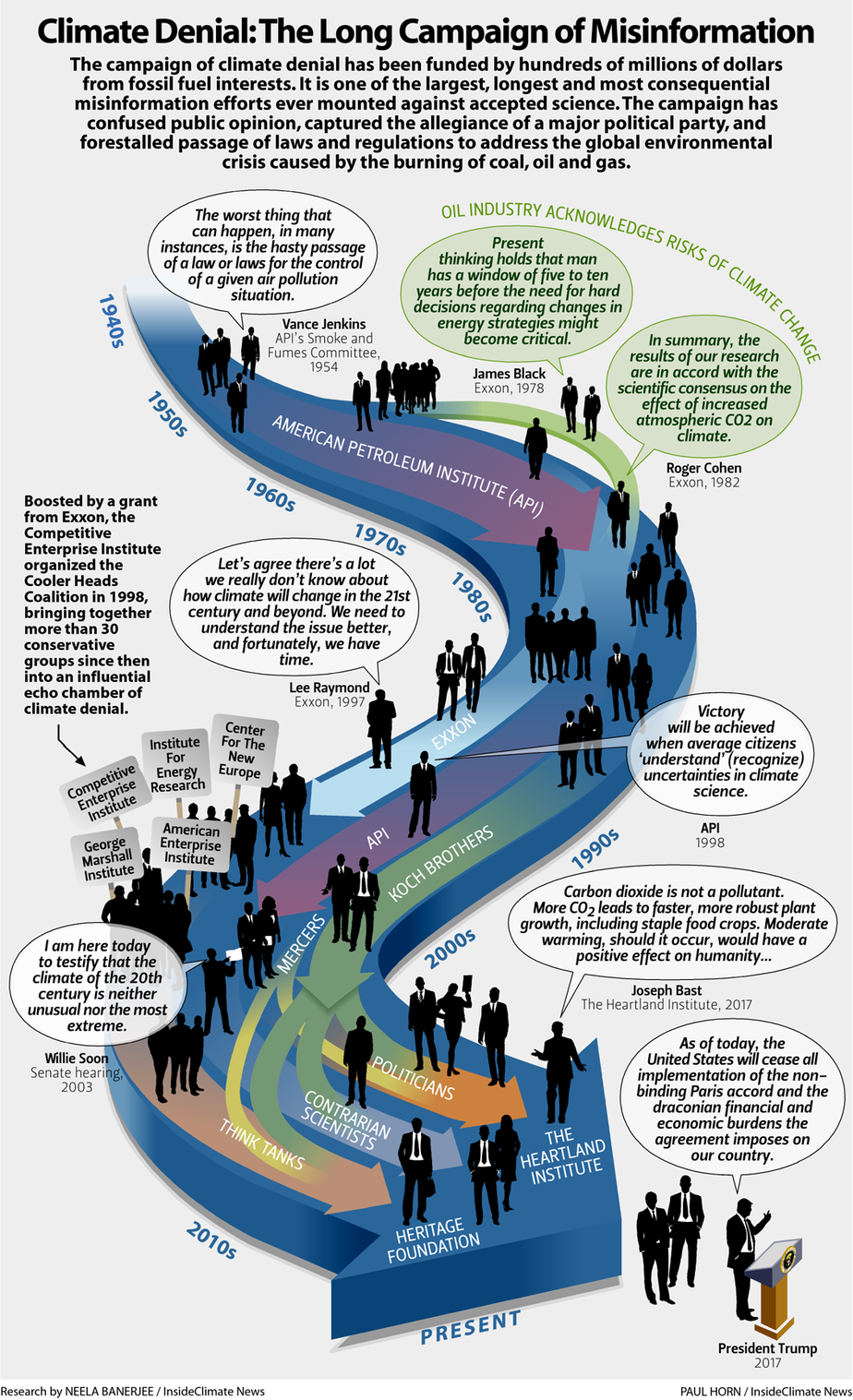
Inside Climate did a nice job summarizing the past 70 years of climate denial by fossil fuel interests, including links to key historical references. Read it here. They also made this visual, which is helpful.
Awhile back we stopped at Duarte’s Tavern in Pescadero, CA, which was founded roughly a century ago (I think the building predates the restaurant). They still had a couple of non-functional gas lamps on the wall, with wicks and everything. I took a couple of photos, which I show below. They look a lot like Coleman lanterns (roughly the same tech).
PS. We highly recommend Duarte’s for pie, grilled fish, and their amazing crab melts, among other things. If in the neighborhood, be sure to stop by.
Yesterday (May 31, 2018) I talked at the Foothill College Solutions conference about climate solutions, summarizing what I’ve learned in three decades of studying how to solve the climate problem. Here’s the main message:
We need to reduce emissions as much as possible, as fast as possible, starting as soon as possible. Everything else is noise.
I focus on the need for urgent action and the tools that give me hope that we can ultimately solve this problem. You can download a PDF of the talk here.
December 8, 2017. Beginner’s guide series on cryptoassets. Medium. This is a list of guides by the author, including beginner’s guides to: Ethereum, Monero, Litecoin, Ethereum tokens, 0x, Tezos, Bitcoin Cash, Decred, Zcash, and IOTA.
Because of recent interest in the electricity use of Bitcoin mining, I asked my colleague Zach Schmidt to create a reasonably comprehensive list of articles and reports on this topic. As we update this list we’ll create new blog posts so that the latest version is usually at the top of the heap on Koomey.com.
Please email me if you see a new article that seems especially well written and authoritative and we’ll add it to the list. There’s precious little credible information on this topic nowadays, but I hope that will change soon. My own summary of the key issues is still in process, but hopefully this list of articles will be of use in the meantime.
The most credible academic estimates are at the bottom of this post. Not surprisingly, the news articles are by far the majority of writing on this topic.
“It was in that moment that I realized that if our children look back to how we failed them, it will not have been for lack of scientific understanding or even technological prowess; it will have been due, fundamentally, to cowardice. A profound cowardice among those who actually do have a choice in this matter, a cowardice that confuses arrogance with intelligence, pettiness with importance, and, most fatally, comfort with necessity. “